人脸识别 之 OpenCV (Haar、DNN)人脸检测
- 人脸识别
- 2021-08-25
- 129热度
- 0评论
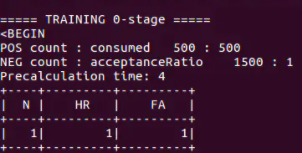
一、基于 OpenCV Haar:
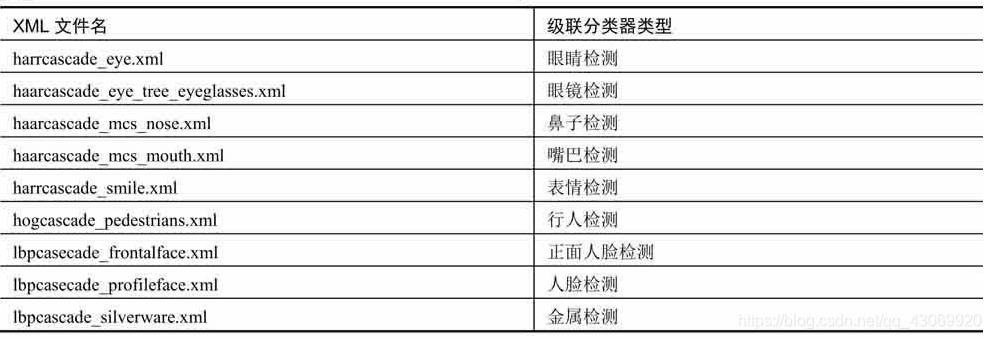

二、基于 OpenCV DNN:
OpenCV 3.4 版本之前自带的人脸检测器是基于 Haar+Adaboost 的,速度还可以,但是检出率很低,误检也很多,脸的角度稍大就检不出来,还经常会把一些乱七八糟的东西当做人脸,实在不敢恭维。
OpenCV 3.4 版本主要增强了 dnn模块,特别是添加了对 faster-rcnn 的支持,并且带有 OpenCL加速,效果还不错。
支持 Caffe、Tensorflow 模型:
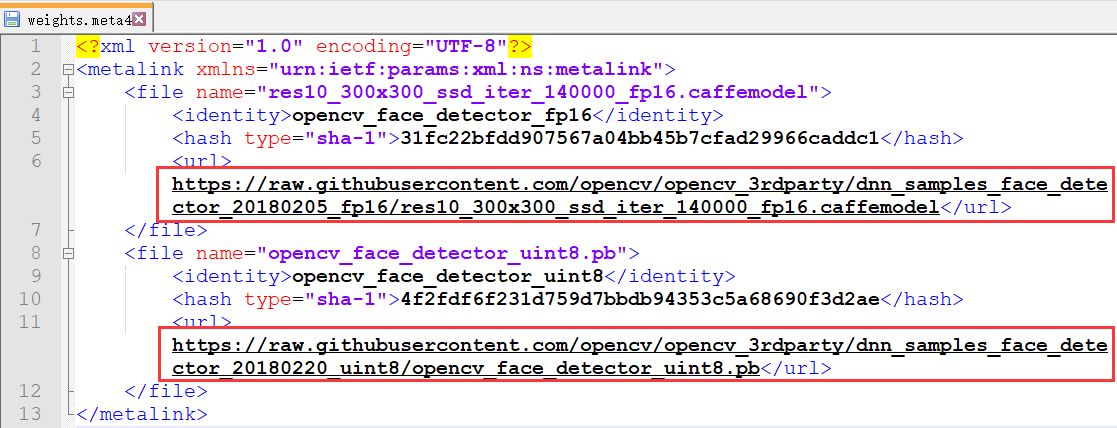
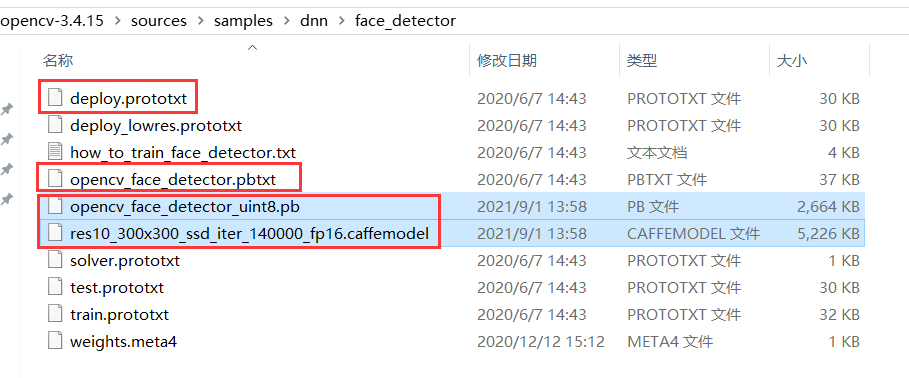
1、Caffe 模型,需要两个文件:模型参数 deploy.prototxt 位于 D:\opencv-3.4.15\sources\samples\dnn\face_detector ,文件中定义了每层的结构信息;模型配置文件即模型框架:res10_300x300_ssd_iter_140000_fp16.caffemodel,可执行 download_weights.py 下载,或者直接访问 weights.meta4 文件里的链接下载。
2、Tensorflow 模型,需要两个文件:opencv_face_detector.pbtxt 位于 D:\opencv-3.4.15\sources\samples\dnn\face_detector ,opencv_face_detector_uint8.pb,可执行 download_weights.py 下载,或者直接访问 weights.meta4 文件里的链接下载。
其中 Tensorflow 版本的模型做了更加进一步的压缩优化,大小只有2MB左右,非常适合移植到移动端使用,实现人脸检测功能,而 Caffe 版本的是 fp16 的浮点数模型,精准度更好。
Python 源码、测试效果:
import cv2
import numpy as np
import os
face_database_folder_path = "../face_img"
face_database_imgs = []
face_database_labels = []
face_database_names = []
index = 1
for filename in os.listdir(face_database_folder_path):
if filename.endswith('.jpg'):
print('处理第 %s 张图片' % index)
else:
continue
image = cv2.imread(face_database_folder_path + '/' + filename)
gray_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
face_database_imgs.append(gray_img)
face_database_labels.append(index - 1)
face_database_names.append(filename.split('.')[0])
index += 1
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 使用之前训练好的模型
# recognizer.read('my_trainner.yml')
recognizer.train(face_database_imgs, np.array(face_database_labels))
# 保存模型,方便下次直接使用训练好的模型
# recognizer.save('my_trainner.yml')
input_shape = (300, 300)
mean = (104.0, 177.0, 123.0) # 这个是在Net训练的时候设定的,在训练的时候 transform_param 中设置的。
# Caffe 模型
net = cv2.dnn.readNetFromCaffe("deploy.prototxt", "res10_300x300_ssd_iter_140000_fp16.caffemodel")
# Tensorflow 模型
# net = cv2.dnn.readNetFromTensorflow("opencv_face_detector_uint8.pb", "opencv_face_detector.pbtxt")
cameraCapture = cv2.VideoCapture(0)
success, image = cameraCapture.read()
while success and cv2.waitKey(1) == -1:
success, image = cameraCapture.read()
# image = cv2.resize(image, input_shape)
(h, w) = image.shape[:2]
# 构造blob
blob = cv2.dnn.blobFromImage(image, 1.0, input_shape, mean)
# 检测人脸
net.setInput(blob)
detections = net.forward()
default_confidence = 0.5
bboxes = []
# 遍历
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
# 过滤弱检测
if confidence > default_confidence:
# 获取检测框坐标
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
bboxes.append([startX, startY, endX, endY, confidence])
if len(bboxes) == 0:
print('未检测到人脸')
else:
for startX, startY, endX, endY, confidence in bboxes:
# 绘制框
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if (startY - 10) > 10 else (startY + 10)
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.putText(image, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 1)
# 生成灰度图
gray_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
predict_image = gray_img[startY:endY, startX:endX]
# cv2.imshow("Camera", predict_image)
# cv2.waitKey(10)
label, confidence = recognizer.predict(predict_image)
print('Label:%s,Name:%s,confidence:%.2f' % (label, face_database_names[label], confidence))
cv2.putText(image, face_database_names[label], (startX, startY - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2)
cv2.imshow("Camera", image)
if cv2.waitKey(10) & 0xFF == ord("q"):
break
cameraCapture.release()
cv2.destroyAilwindows()
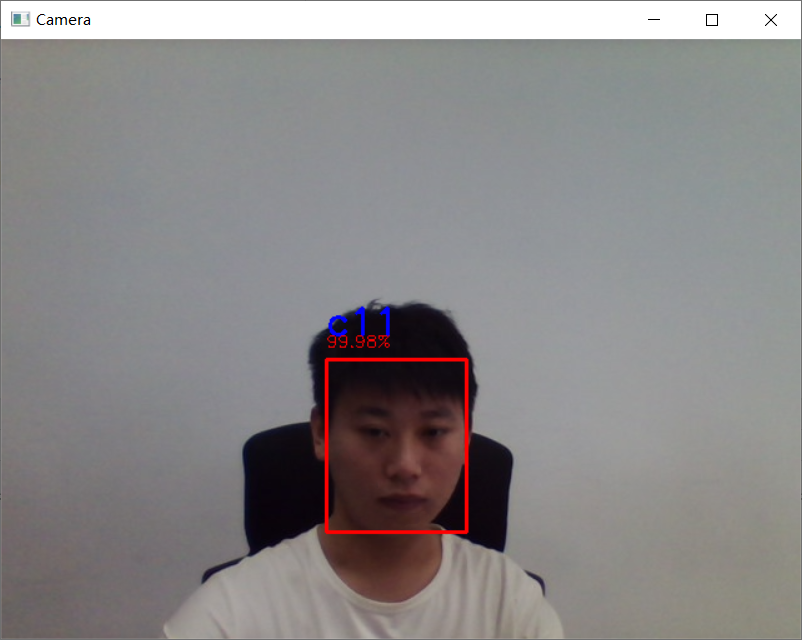
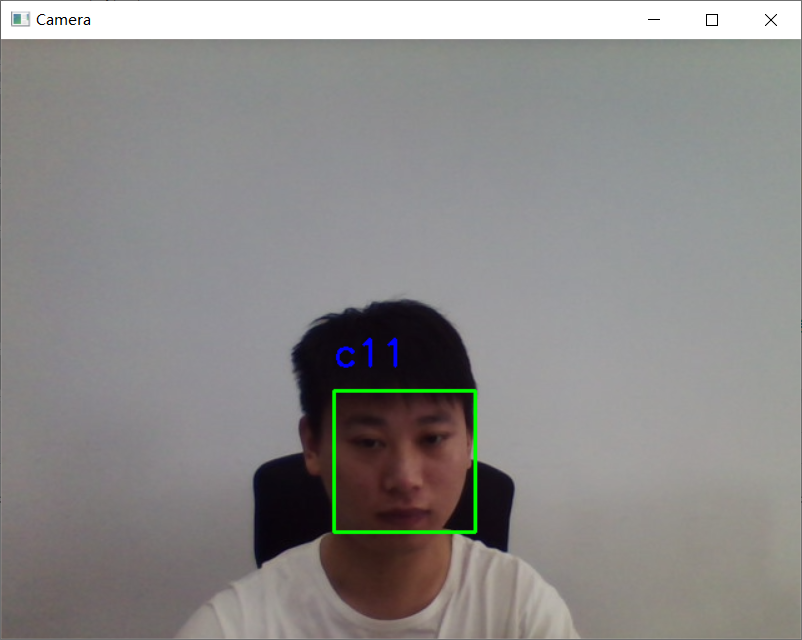
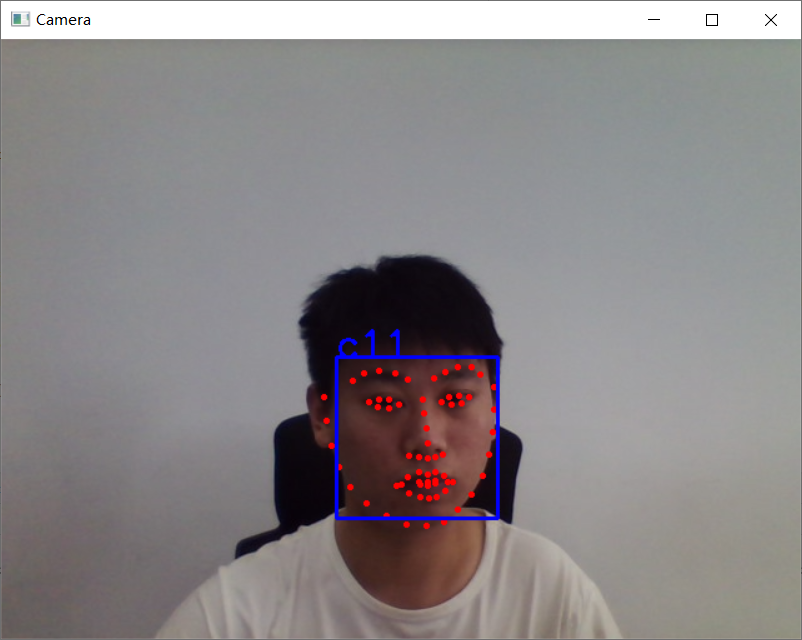
检测效果明显好于 Haar,效果图如下:

 鲁ICP备19063141号
鲁ICP备19063141号
 鲁公网安备 37010302000824号
鲁公网安备 37010302000824号