Mycat2 读写分离、分库分表
- MySQL
- 2023-04-12
- 107热度
- 0评论
Mycat2文件下载:
提取码:6ff7
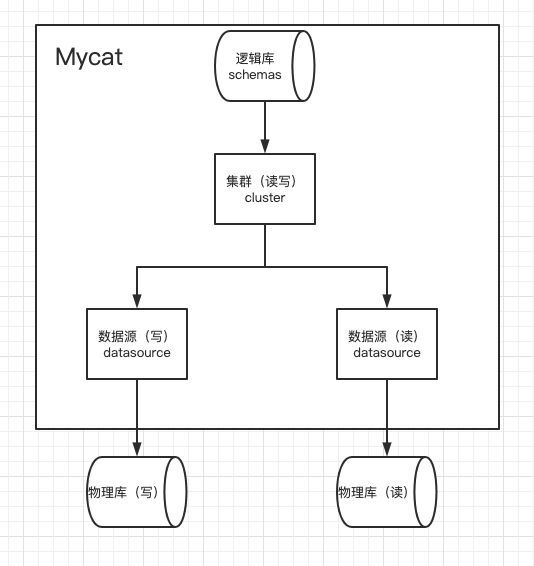
一、Mycat2 读写分离
1、安装 JDK 1.8
2、配置MySQL(本次测试使用的root)
#创建mycat用户
CREATE USER 'mycat'@'%' IDENTIFIED BY '123456';
#必须要赋的权限mysql8才有的,分布式事务
GRANT XA_RECOVER_ADMIN ON *.* TO 'mycat'@'%';
#视情况赋权限
GRANT ALL PRIVILEGES ON *.* TO 'mycat'@'%' ;
flush privileges;
3、下载安装包壳、JAR包
4、解压安装包壳,将 mycat2-1.22-release-jar-with-dependencies.jar 文件复制到 \mycat2-install-template-1.21\mycat\lib 文件夹下。
5、#修改数据源
\mycat\conf\datasources\prototypeDs.datasource.json
6、修改文件权限
chmod -R 777 mycat/bin/
7、安装mycat
CMD 进入 \mycat\bin 目录
mycat install
mycat start
mycat status
mycat restart
8、连接测试,默认端口:8066
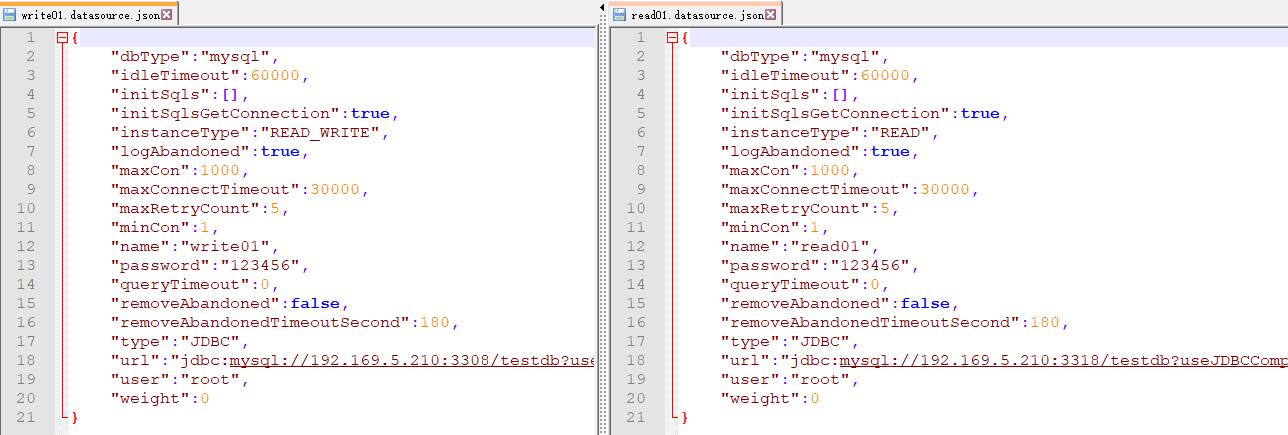
9、使用注释方式添加数据源
/*+ mycat:createDataSource{ "name":"write01","url":"jdbc:mysql://192.169.5.210:3308/testdb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;
/*+ mycat:createDataSource{ "name":"read01","url":"jdbc:mysql://192.169.5.210:3318/testdb?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"123456" } */;
/*+ mycat:showDataSources{} */;
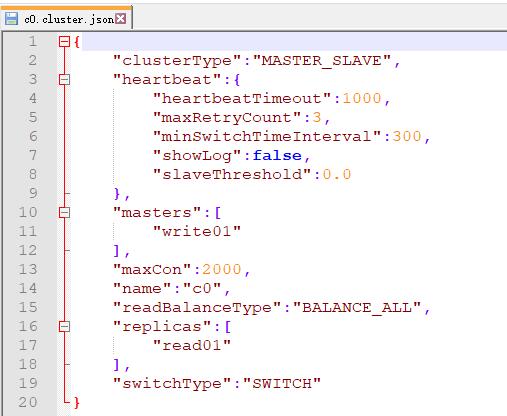
10、添加集群信息
/*! mycat:createCluster{"name":"c0","masters":["write01"],"replicas":["read01"]} */;
/*+ mycat:showClusters{} */;
11、创建逻辑库
/*+ mycat:createSchema{ "customTables":{},"globalTables":{},"normalTables":{},"schemaName":"testdb","shardingTables":{},"targetName":"c0"} */;
12、连接测试读写分离
二、Mycat2 分库分表
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面。
如下图:系统被切分成了,用户,订单交易,支付几个模块。
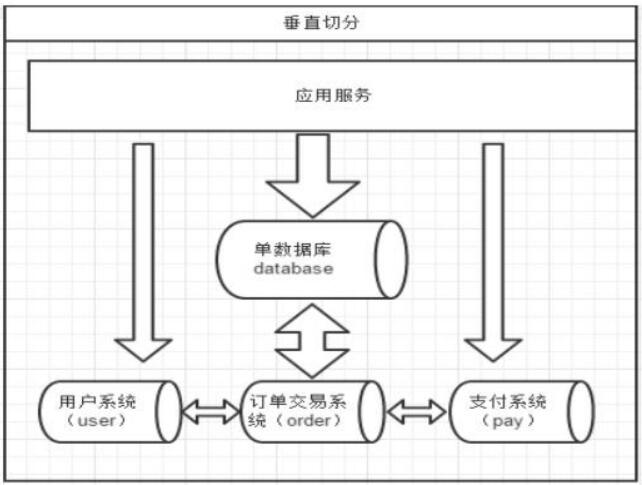
在两台主机上的两个数据库中的表,能否关联查询?
答案:不可以关联查询。
全局序列:
Mycat2 在 1.x 版本上简化全局序列,自动默认使用雪花算法(引入了时间戳和 ID 保持自增的分布式 ID 生成算法)生成全局序列号,如不需要 Mycat 默认的全局序列,可以通过配置关闭自动全局序列。
如果不需要使用 mycat 的自增序列,而使用 mysql 本身的自增主键的功能,需要在配置中更改对应的建表 sql,不设置 AUTO_INCREMENT 关键字,这样 mycat 就不认为这个表有自增主键的功能,就不会使用 mycat 的全局序列号。对应的插入 sql 在 mysql 处理,由 mysql 的自增主键功能补全自增值。
雪花算法:

分库的原则:
有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
1、广播表(全局表)
CREATE TABLE testdb.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
2、分片表(分库分表)
CREATE TABLE testdb.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(customer_id)
tbpartition BY mod_hash(customer_id)
tbpartitions 1 dbpartitions 2;
-- dbpartition 设置数据库分片规则;tbpartition 设置表分片规则
-- tbpartitions 1 dbpartitions 2 配置分片数。表分成一片,数据库分成两片(即两个数据库各分1片)
注意:这里我在执行的时候遇到了一个问题,报错 can not found c0。是由于我在之前准备环境的时候准备的c1。这里我们把c1改成c0即可。
3、插入数据测试分库分表
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
SELECT * FROM orders;
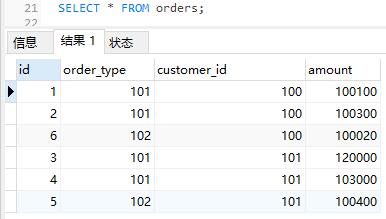
我们可以看到数据是按照分片键排序的,而不是按照ID排序的。这说明数据是分布在不同是库,然后分别查询拼接起来的。我们打开物理库也可以看到数据分布到了不同的物理表上。
4、ER 表
CREATE TABLE testdb.orders_detail(
`id` BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(order_id)
tbpartition BY mod_hash(order_id)
tbpartitions 1 dbpartitions 2;
#查看配置的表是否具有 ER 关系,其中groupId表示相同的分组,在该分组的表具有相同的存储分布。
/*+ mycat:showErGroup{}*/
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
SELECT * FROM orders o INNER JOIN orders_detail od ON od.order_id=o.id;
通过查询我们发现orders表与orders_detail表中order_id相同的并没有分布在同一个数据库。
注:
#上述两表具有相同的分片算法,但是分片字段不相同。
# Mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推。
# Mycat2 无需指定 ER 表,是自动识别的,具体看分片算法的接口。
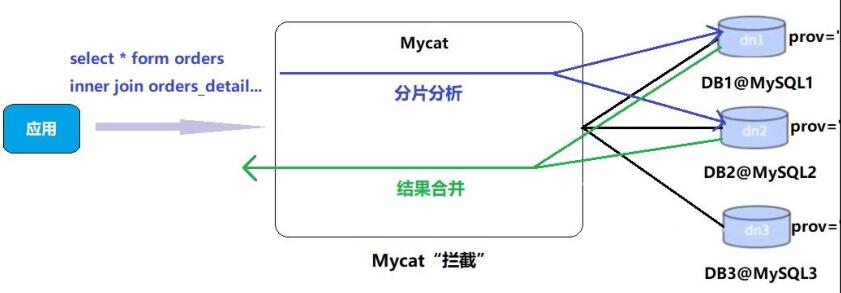
关联查询原理:

 鲁ICP备19063141号
鲁ICP备19063141号
 鲁公网安备 37010302000824号
鲁公网安备 37010302000824号