Agent Skills 详解
- 人工智能
- 2026-03-10
- 249热度
- 0评论
1. 引入Skills
1.1 Skills是什么?
Skill本质就是一个prompt(一个任务模版),在claude code加载skill,最终都是把skill.md、references/、asset/、scripts、合并成一个prompt。
举例:
System: You are Claude, a helpful AI assistant created by Anthropic.
You are knowledgeable, thoughtful, and aim to be helpful.
[Claude 的基础指令]
<span style="color: #ff0000;"><strong>--- Skills Loaded ---</strong></span>
## PDF Skill
[pdf-skill/SKILL.md 的完整内容]
You are an expert in PDF processing...
When extracting text from PDFs:
- Preserve formatting
- Handle tables correctly
...
[pdf-skill/references/best-practices.md 的内容]
## Email Extractor Skill
[email-extractor/SKILL.md 的完整内容]
You specialize in extracting structured information from emails...
When processing emails:
- Extract sender, subject, date
- Identify key action items
...
[email-extractor/references/email-patterns.md 的内容]
--- End of Skills ---
User: [用户的实际输入]
1.2 Skills Vs 直接写Prompt区别
|
特性
|
直接写 Prompt
|
使用 Skill
|
|
长度
|
需要每次输入完整指令
|
一次定义,重复使用
|
|
管理
|
分散在各处
|
集中在 Skill 文件夹
|
|
版本控制
|
难以追踪变化
|
Git 管理,有历史记录
|
|
分享
|
复制粘贴 prompt
|
打包成 .zip 或 Git 仓库
|
|
组合使用
|
手动合并多个 prompt
|
可以同时加载多个 Skills
|
1.3 Skills作用
1、定义模板 workflow,提高可重用性:一次编写,到处使用,标准化工作流程。
2、集成和编排工具,突破上下文限制:
- 将相关工具组合在一起,定义工具的使用时机和顺序。
- Skills 采用了独特的 “渐进式披露” 架构,像一本组织良好的手册,从目录开始,然后是特定章节,最后是详细附录,Skills 让 Claude 只在需要时加载信息 Claude。
层级 1: Skill 名称 + 描述(总是加载)
层级 2: SKILL.md 完整内容(相关时加载)
层级 3+: 额外的参考文件(按需加载)
3、将特定领域的专业知识编码进 Skill,让通用 AI 具备特定领域的专业能力。
2. Skill目录
2.1 标准结构
Skill本质就是一个prompt(一个任务模版),为了保证skill.md中内容简洁,对于比较复杂的skill.md 可以将数据归类到references/scripts/asset目录下。
一个标准的Skill目录如下:
skill-name/
├── SKILL.md # 必需:Skill 的入口文件和核心指令
│ ├── YAML frontmatter(元数据)
│ └── Markdown 内容(指令)
├── scripts/ # 可选:存放可执行的辅助脚本
│ ├── script1.py
│ └── script2.sh
├── references/ # 可选:存放供 AI 参考的外部文档、Schema 等
│ ├── api_docs.md
│ └── schema.md
└── assets/ # 可选:存放报告模板、图片等静态资源
├── template.html
└── logo.png
SKILL.md 详解
SKILL.md 是 Skill 的灵魂,它由两部分组成:YAML Frontmatter (元数据) 和 Markdown Body (指令主体)。
- YAML Frontmatter (元数据区):位于文件最顶端,用---包裹,用于定义 Skill 的基本信息、依赖和配置。
- Markdown Body (指令区):跟在 YAML 之后,这里是你放置核心提示词的地方,其结构与我们之前介绍的 “通用 Skill 设计模板” 完全一致,包含角色设定、目标、输入输出要求、示例、限制等。
---
name: email-extractor
description: "Extracts email addresses from a block of text."
metadata:
version: 0.1.0
author: "Your Name"
inputs:
- name: "text_block"
type: "string"
description: "The text to search for emails."
required: true
---
你是一位数据处理专家。你的任务是从用户提供的文本中,找出所有格式合法的电子邮件地址。
## 输出格式
请将找到的所有电子邮件地址以 JSON 列表的形式输出。如果没找到,则返回一个空列表。
## 示例
- ** 输入:** "Contact me at test@example.com or support@domain.org."
- ** 输出:**
```json
["test@example.com", "support@domain.org"]
```
## 质量检查
- [ ] 结果是否为 JSON 数组格式?
- [ ] 是否处理了没有邮件地址的情况?
scripts 目录
此目录保存封装的的脚本或者代码。
references 目录
存放供 AI 在执行任务时 “阅读” 的背景材料,尤其适用于涉及专业领域知识的 Skill,可以当成知识库。
- 存放大量示例数据。
- 技术规范文档。例如,一个用户 JSON 对象的字段定义(user_id, username, email)、数据类型、是否必填和示例值。
assets 目录
用于存放 Skill 在生成结果时需要用到的静态资源:
- 模板文件。比如 Skill 的目标是生成一份 HTML 报告,这里可以存放报告的模板文件。模板中可以使用占位符(如 {{ title }} 和 {{ content }}),AI 的任务就是生成填充这些占位符的内容。
- 配置文件。
- 多媒体:比如报告或产出物中需要用到的图片、Logo 等。
2.2 Skill 中有 script、references、asset 目录,这些目录是做什么的?正常不是只有一个 skill.md 不就行了?
skill本质就是一个提示词 来构建的任务模版,为了保证skill.md中prompt简洁,对于比较复杂的skill.md 可以将数据归类到references、scripts、asset目录下。
正常情况简单场景 (只需 skill.md),比如:提取邮件地址这种简单任务。
email-extractor/
└── skill.md
复杂场景 ,需要完整结构:
email-extractor/
├── skill.md # 核心逻辑
├── scripts/
├── preprocess.js # 清洗输入
└── validate.js # 验证输出
├── references/ │
├── rfc5322.md # 邮件标准文档
└── assets/
├── output-template.json # 输出模板
└── icon.svg # Skill 图标
选择哪种方式?大概80% 的 Skills 只需要 skill.md。
|
只用 skill.md
|
需要额外目录
|
|
提示词 < 500 行
|
提示词 > 500 行或需要分模块
|
|
无需编程逻辑
|
需要前/后处理脚本
|
|
示例在提示词内就够
|
大量示例数据
|
|
个人使用
|
团队协作/发布到社区
|
2.3 Skill 的 script 也是在 prompt 提供的样例,llm 本身不执行 script 吧?
LLM本身不执行script,而是:
- LLM的角色:根据prompt中的示例和指令,生成符合格式的script代码。
- Script的执行:由外部的执行引擎/运行时环境来解析和执行这些script。
具体流程是这样的:
用户请求
↓
LLM分析并生成技能调用的script
↓
返回script给调用方
↓
外部执行引擎解析script
↓
调用实际的工具/API
↓
返回结果
类比理解:
- LLM就像一个“代码生成器”,根据文档示例写出符合规范的代码。
- 但它不是“编译器”或“解释器”,不负责真正运行这些代码。
- 真正的执行由外部系统(如:function calling 框架、MCP服务器等)完成。
3. 创建 Skill
3.1 直接使用官网库
https://github.com/anthropics/skills,这个项目是 Anthropic 的 Skills 系统的公开仓库。Skills 是一些指令、脚本和资源的文件夹集合,Claude 可以动态加载它们来提升在特定任务上的表现。
第一步:添加市场。这个命令是将 anthropics/skills 这个 GitHub 仓库注册为一个插件市场源,类似于添加一个“商店”,安装在~/.claude/plugins/marketplaces。
# skill没有公开市场平台,只有这个公共代码库,都是在本地添加市场。
/plugin marketplace add anthropics/skills
第二步:安装具体的 Skills。这个命令才是真正安装具体的 Skills 到你的 Claude Code 中。
/plugin install document-skills@anthropic-agent-skills
# 或
/plugin install example-skills@anthropic-agent-skills
第三步 执行 /plugin list
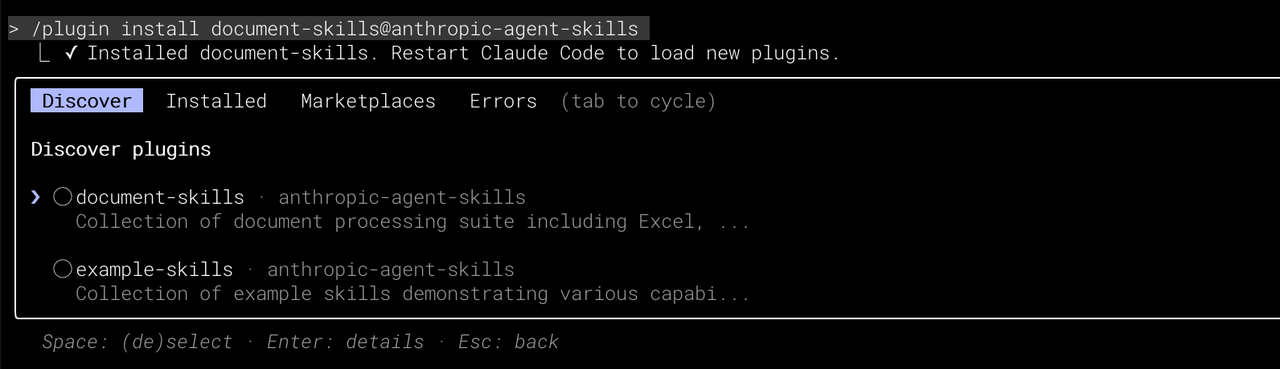
第四步:测试一个demo。执行如下会在本地创建一个docx的文档:
请帮我创建一个 Word 文档,内容如下:
标题:2024年度工作总结
副标题:技术部门
正文包含三个部分:
1. 项目完成情况 - 今年完成了5个重要项目
2. 团队成长 - 团队从10人扩展到15人
3. 明年规划 - 计划启动3个新项目
请使用专业的格式,包含适当的标题样式和段落间距。
注意:这里不需要显示指定 @document_skills ,直接在对话框输入上面文本就行。一般在测试某一个skill时,才指定skill。
3.2 创建自定义Skill
方式1:使用官方脚本创建
下载官方项目(https://github.com/anthropics/skills),进入到当前目录的 skill-creator/scripts,然后执行如下命令,在new下创建了一个extract-email目录

生成如下:
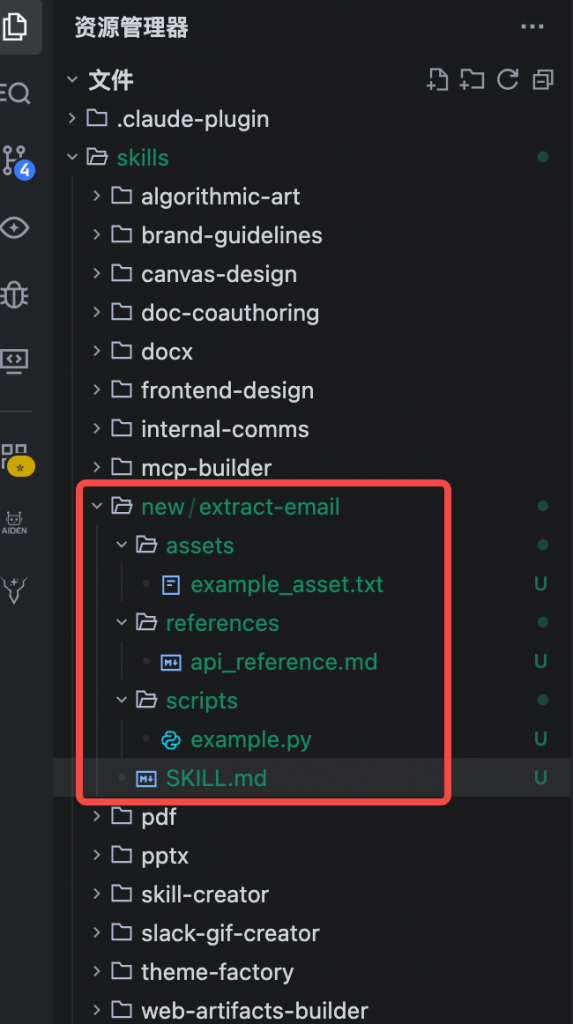
方式2:手动创建
安装目录格式手动创建上面的目录和文件
---
name: email-extractor
description: "Extracts email addresses from a block of text."
metadata:
version: 0.1.0
author: "Your Name"
inputs:
- name: "text_block"
type: "string"
description: "The text to search for emails."
required: true
---
你是一位数据处理专家。你的任务是从用户提供的文本中,找出所有格式合法的电子邮件地址。
## 输出格式
请将找到的所有电子邮件地址以 JSON 列表的形式输出。如果没找到,则返回一个空列表。
## 示例
- ** 输入:** "Contact me at test@example.com or support@domain.org."
- ** 输出:**
```json
["test@example.com", "support@domain.org"]
```
## 质量检查
- [ ] 结果是否为 JSON 数组格式?
- [ ] 是否处理了没有邮件地址的情况?
4. Skill 加载机制
如何读取skill的skill.md、references、assetss的信息?最终还是构建一个prompt:
1. 启动:扫描 skills 目录,索引所有 Skill
2. 调用:用户通过 @skill-name 触发
3. 加载和组装Context
- 读取 skill.md (必需) + references + assets
- 构建完整的 System Promp
4. 执行:调用 Claude API
阶段 1:启动时扫描
默认流程
Claude Code 启动
↓
扫描 skills/ 目录
↓
解析每个 skill.md 的 frontmatter
↓
构建 Skill 索引(name, description)
↓
准备就绪
Claude Code 会在特定位置查找 Skills:
# macOS/Linux
~/.config/claude-code/skills/
# Windows
%APPDATA%\claude-code\skills\
# 或项目本地
./.claude/skills/
skill.md
---
name: email-extractor
description: "Extracts emails from text"
---
你是邮件提取专家。从用户文本中提取所有邮件地址。
输出格式: JSON 数组
references/patterns.md
# 常见邮件格式
- 标准格式: user@domain.com
- 带加号: user+tag@domain.com
- 子域名: user@mail.company.com
assets/template.json
{
"emails": [],
"count": 0,
"timestamp": ""
}
激活配置config.json
config.json是把skill的所有信息生成prompt,都合并到context。
# .claude/config.json
{
"active_skills": ["pdf-skill","email-extractor"]
}
当你配置 active_skills 时,Claude Code 做的事情
1. 启动时读取 config.json
↓
2. 找到指定的 Skills 目录
~/.claude/plugins/.../pdf-skill/
~/.claude/plugins/.../email-extractor/
↓
3. 读取每个 Skill 的内容
- SKILL.md 的内容
- references 下的文档
- 可能还有其他元数据
↓
4. 组合成一个大的 System Prompt
↓
5. 每次对话都附加这个 System Prompt
对比下有激活和无激活的system prompt:
1、默认(无激活配置conifig.json)。每次需要动态的加载sklill,即根据用户输入,圈定具体的skill,然后再加载skill。所以默认情况下system prompt原始内容没有load skill的信息。
System: You are Claude, a helpful AI assistant created by Anthropic.
You are knowledgeable, thoughtful, and aim to be helpful.
[Claude 的基础指令]
2、 有激活config.json。预加载 Skills 后的 System Prompt,保证每次skill都是生效,行为一致可预测,但是每次会消耗更多的tokens。
System: You are Claude, a helpful AI assistant created by Anthropic.
You are knowledgeable, thoughtful, and aim to be helpful.
[Claude 的基础指令]
--- Skills Loaded ---
## PDF Skill
[pdf-skill/SKILL.md 的完整内容]
You are an expert in PDF processing...
When extracting text from PDFs:
- Preserve formatting
- Handle tables correctly
...
[pdf-skill/references/best-practices.md 的内容]
## Email Extractor Skill
[email-extractor/SKILL.md 的完整内容]
You specialize in extracting structured information from emails...
When processing emails:
- Extract sender, subject, date
- Identify key action items
...
[email-extractor/references/email-patterns.md 的内容]
--- End of Skills ---
User: [用户的实际输入]
阶段 2:用户调用 Skill
正常情况下是通过llm自动识别的,不需要显示指定。在测试阶段可以使用 @ 语法显示调用。
@email-extractor "Contact me at test@example.com"
阶段 3:加载和组装Context
1. 读取 skill.md
├── 解析 YAML frontmatter (metadata)
└── 读取 Markdown 正文 (instructions)
2. 加载 references
├── 读取所有 .md, .txt, .json 文件
└── 作为附加上下文
3. 加载 assets
├── 读取模板、配置文件
└── 如果需要,编码为 base64
4. 组装最终 prompt
├── System: skill.md 的指令
├── Context: references 的内容
└── User: 用户的实际输入
组装后的实际prompt:
--
System Message:
---
你是邮件提取专家。从用户文本中提取所有邮件地址。
输出格式: JSON 数组
## 参考资料
### patterns.md
# 常见邮件格式
- 标准格式: user@domain.com
- 带加号: user+tag@domain.com
- 子域名: user@mail.company.com
## 输出模板
{
"emails": [],
"count": 0,
"timestamp": ""
}
---
User Message:
请从以下文本中提取邮件: "Contact us at info@example.com..."
5. 发布Skill:创建好的skill如何加入到Claude Code
方式1:放置源码-本地使用
1. 包含两个目录
- 个人的 Skills
~/.claude/skills/
└── my-skill/
├── SKILL.md # 源码
├── scripts/
│ └── helper.py # 源码
└── resources/
└── data.json # 源码
- 项目 Skills:如果只是某一project下,建立一个skill目录,然后把原始的skill放在skill目录下就行。
your-project/
├── skills/
│ ├── my-skill/
│ │ ├── src/
│ │ │ └── index.ts
│ │ ├── package.json
│ │ ├── tsconfig.json
│ │ └── README.md
│ └── another-skill/
│ └── ...
└── 其他目录
2. FAQ
Q:定义一个cluade skill,在当前project的skills目录下放置的是skill的原始目录,还是通过pacakage打包的产物?
A:在项目中,skills 目录下通常放置的是 skill 的原始源代码目录,而不是打包后的产物。
your-project/
├── skills/
│ ├── my-skill/
│ │ ├── src/
│ │ │ └── index.ts
│ │ ├── package.json
│ │ ├── tsconfig.json
│ │ └── README.md
│ └── another-skill/
│ └── ...
└── 其他目录
Q:如果要在 .claude/config.json 配置 { “active_skills”: [“email-extractor”] },那么是否需要先打包发布呢?
A:不需要先打包发布。在 .claude/config.json 中配置本地 skill 时,可以直接引用本地的源代码目录。
{
"skills": {
"email-extractor": {
"path": "/absolute/path/to/skills/email-extractor"
}
},
"active_skills": ["email-extractor"]
}
方式2:通过 /plugin 发布自己的 Skills 的方式
# 1. 创建你自己的 Skills 仓库
# 例如:https://github.com/your-username/my-skills
# 2. 添加你的仓库作为 marketplace
/plugin marketplace add your-username/my-skills
# 3. 从你的市场安装
/plugin install your-skill@your-marketplace-name
anthropics/skills/代码库 VS Plugin Marketplace区别:
1. GitHub 仓库 (anthropics/skills)
- 这是一个示例和参考仓库
- 包含 Anthropic 官方提供的示例 Skills
- 主要用于:学习如何创建 Skills,参考最佳实践;使用 Anthropic 提供的官方 Skills
2. Claude Code Plugin Marketplace
- 这是 Claude Code 的插件市场系统
- 可以从任何 GitHub 仓库添加为 marketplace 源
- 你可以创建自己的仓库并添加为市场源
公开 Skills
# 从公开 GitHub 仓库
/plugin marketplace add anthropics/skills
/plugin install document-skills@anthropic-agent-skills
私有Skills
# 方案 1: 从公司私有 GitHub 仓库
/plugin marketplace add your-company/internal-skills
# 方案 2: 从本地路径
/plugin add /company/shared/skills/custom-skill
# 方案 3: 通过 Claude API 上传(完全私有)
# 使用 API 上传 skills,只有你的账号可以访问
方式3:通过 package 发布的场景
使用package (验证 + 依赖分析+ 元数据+ 优化 + 签名 + 压缩)。它不是简单的 zip 命令,而是一个完整的构建和发布流程。
- 下载:https://github.com/anthropics/skills/tree/main/skills/docx
- 进入脚本目录 cd skills/skill-creator/scripts
- 打包并输出到指定目录 ./package_skill.py ~/.claude/skills/company-branding ~/Desktop/
6. Skills 和 MCP
核心区别
Skills
- 本质: 提示词模板/指令集
- 作用: 定义 Claude 如何思考和回应
- 内容: 系统提示、输出格式、示例、质量标准
- 类比: 给 Claude 的“工作手册”或“SOP”
MCP
- 本质: 数据和工具连接协议
- 作用: 让 Claude 访问外部资源
- 内容: 数据库、API、文件系统、搜索引擎等
- 类比: 给 Claude 的“工具箱”
两者关系
┌─────────────────────────────────────┐
│ Claude Skill │
│ (如何处理邮件提取任务) │
│ │
│ ┌───────────────────────────┐ │
│ │ 提示词: 你是数据专家... │ │
│ │ 输出格式: JSON 列表 │ │
│ │ 质量要求: 验证邮件格式 │ │
│ └───────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────┐ │
│ │ allowed-tools: │ │
│ │ - gmail-mcp (读取邮件) │ ←─┐ │
│ │ - database-mcp (存储) │ │ │
│ └───────────────────────────┘ │ │
└─────────────────────────────────│─┘
│
┌─────────────┴──────────────┐
│ MCP Servers │
│ (提供实际数据和功能) │
│ │
│ • Gmail API │
│ • PostgreSQL │
│ • File System │
│ • Web Search │
└────────────────────────────┘
协同工作示例
假设你要构建一个“客户邮件分析”系统:
Skill 定义 (skill.md):
---
name: customer-email-analyzer
description: "Analyzes customer emails and extracts key information"
allowed-tools:
- gmail-mcp
- crm-database-mcp
---
你的任务是分析客户邮件并提取:
1. 客户情绪 (正面/负面/中性)
2. 关键问题
3. 紧急程度
输出格式: JSON
MCP 提供能力:
- gmail-mcp: 连接 Gmail,读取邮件内容
- crm-database-mcp: 连接 CRM 数据库,查询客户历史
执行流程:
- Skill 告诉 Claude 如何分析邮件
- MCP 让 Claude 能够读取 Gmail 中的实际邮件
- Skill 指导 Claude 按指定格式输出分析结果
- MCP 让 Claude 能够将结果存入 CRM
加载方式
Skills(技能):是渐进式加载的——Claude 可以按需读取特定的 SKILL.md 文件,只加载当前任务需要的技能,不会一次性全部加载。
MCP(Model Context Protocol):不是渐进式加载的。MCP 服务器在启动时就会连接,所有已配置的 MCP 服务器的工具列表会在会话开始时一次性注入到上下文中。这意味着:
- 所有 MCP 工具的定义(schema、描述等)都会占用上下文空间
- 无论你是否用到某个 MCP 工具,它的定义都已经在上下文里了
- 配置的 MCP 服务器越多,上下文开销越大
7. 各种工具路径、文档
| 工具 | 项目路径 | 全局路径 | 官方文档 |
| Antigravity | .agent/skills/ | ~/.gemini/antigravity/skills/ | Antigravity Skills |
| Claude Code | .claude/skills/ | ~/.claude/skills/ | Claude Code Skills |
| Codex | .agents/skills/ | ~/.agents/skills/ | Codex Skills |
| Cursor | .cursor/skills/ | ~/.cursor/skills/ | Cursor Skills |
| Gemini CLI | .gemini/skills/ | ~/.gemini/skills/ | Gemini CLI Skills |
| GitHub Copilot | .github/skills/ | ~/.copilot/skills/ | Copilot Skills |
| OpenCode | .opencode/skills/ | ~/.config/opencode/skills/ | OpenCode Skills |
| Windsurf | .windsurf/skills/ | ~/.codeium/windsurf/skills/ | Windsurf Cascade Skills |

 鲁ICP备19063141号
鲁ICP备19063141号
 鲁公网安备 37010302000824号
鲁公网安备 37010302000824号