大模型术语详解:LLM、Prompt、MCP、Agent、RAG、Embedding、LangChain、vLLM、Ollama、Token 及数据蒸馏
- 人工智能
- 2026-03-02
- 237热度
- 0评论
LLM
Large Language Model 大语言模型,模型多大才被称为大模型并没有统一硬性标准,但行业通常以参数规模和训练数据/算力来衡量 ,语言模型常在 ≥1B 参数开始被称为“大模型”。
比如:
- GPT-2 有 1.5B,早期较大的语言模型
- GPT-3 有 175B
这里1B的B是Billion的意思,也就是参数的个数,1B=10亿,一共有10亿个参数的模型就会被称为大模型。
Prompt
Prompt 提示词,也就是我们输入给大模型的语句。
MCP
Model Context Protocol(模型上下文协议):是一个开放协议,目的是为 LLM应用提供一个标准化接口,使其能够连接外部数据源和各种工具进行交互。
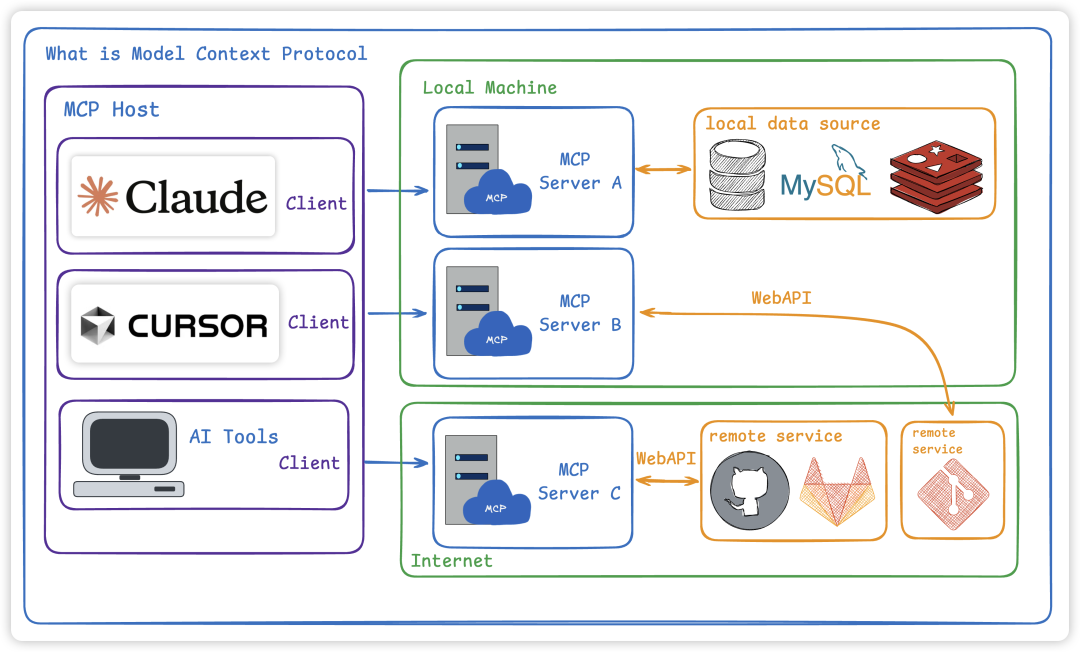
核心在于建立一个标准化的通信层,使得 LLM 能够在处理用户请求或执行任务时,如果需要访问外部信息或功能,可以通过 MCP Client 向 MCP Server 发送请求。
MCP Server 则负责与相应的外部数据源或工具进行交互 ,获取数据并按照MCP协议规范进行格式化,最后将格式化后的数据返回给大型语言模型。
但我们注意一点,大模型是不会自己去调用外部数据源或者工具的,大模型只会告诉我们需要调用哪些工具,而我们需要自己去实现工具的调用。
我们把大模型和MCP融合之后就会出现一个新名字叫智能体 Agent。
Agent
Agent 智能体,我们上面说了大模型只会给我们一个步骤方法 ,不会真正去执行步骤。比如发邮件,大模型只会给出如何发邮件,第一步xxx,第二步xxx。并不会实际帮我们去发邮件,而我们需要把 LLM 整合上 MCP 工具才会真正实现发邮件。
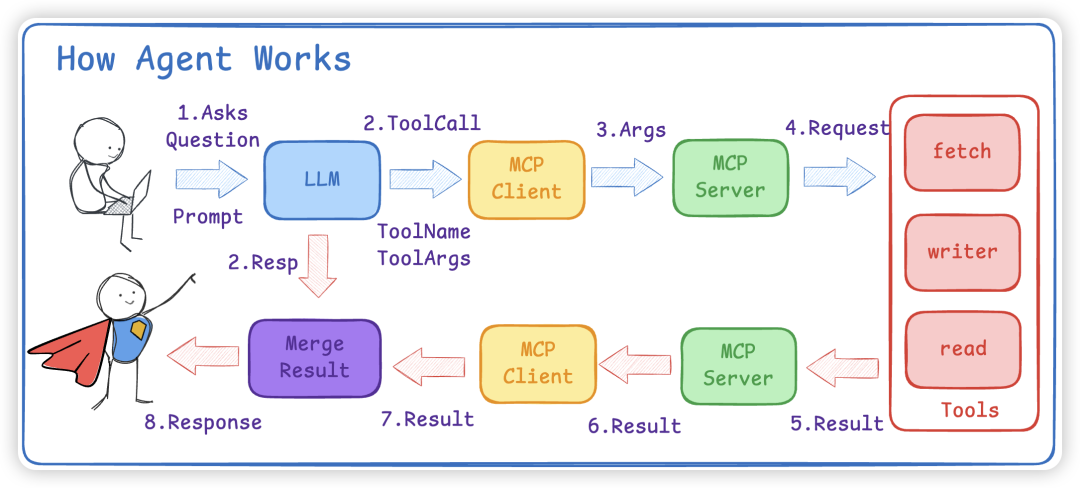
具体流程:
- 给大模型输入提示词:“请帮我给xxx发送一封邮件,告诉他快点更新视频”,并将发邮件的工具 Tool 告诉大模型。
- 大模型会根据工具 Tool 给出一系列的步骤,包括调用什么工具 ToolName,以及调用工具的参数 Args。eg: ToolName = ‘email_sender’、Args = ‘email:xxx, content:快更视频’。
- 我们会将这些参数给到 mcp server。
- mcp server 再进行发送邮件。
- 将结果返回告知用户。
RAG
Retrieval-augmented generation (RAG) 检索增强生成。在用大模型的时候,大家会发现大模型总是一本正经的回答问题,但其实是在胡说八道,这种现象叫 hallucination 幻觉。大模型的本质就是不断的预测下一个生成的文字应该是什么,而选择预测概率中最大的一个。
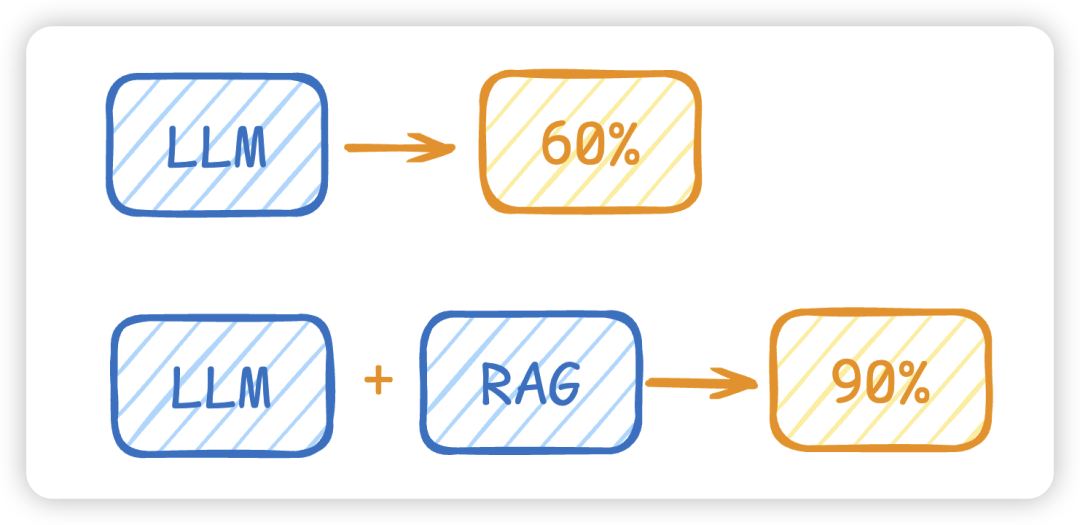
打个比方:LLM 在考试的时候面对陌生的领域,只会写一个解字(因为LLM复习也只是局限于特定的数据集),然后就准备放飞自我了,而此时RAG给了一些提示,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!
RAG的过程如下:
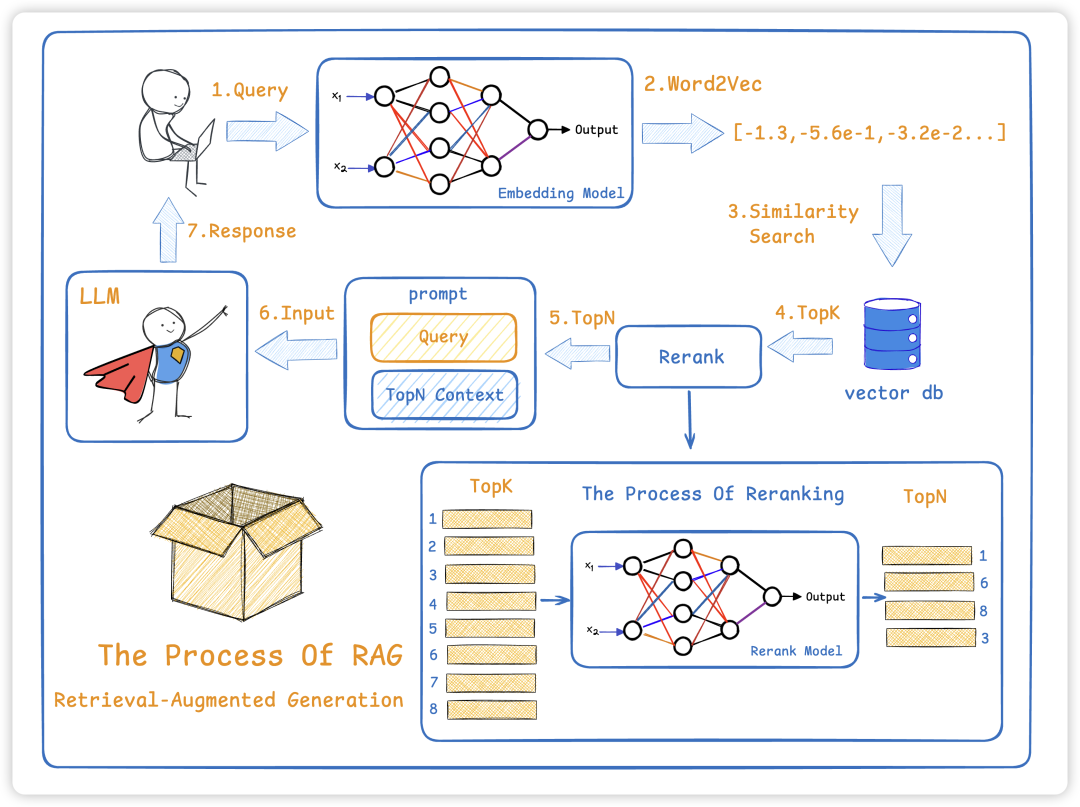
RAG:大模型的“外部知识库”。RAG的核心本质就是「大模型+外部数据」的组合。我们都知道,原生大模型存在两个明显短板:容易产生“幻觉”(输出错误信息)、数据更新不及时,而RAG通过引入外部数据进行增强,就能完美解决这两个问题,让大模型的输出更精准、更贴合实时需求。
下图是RAG最基础的技术架构与工作流程 ,可直接对照理解:
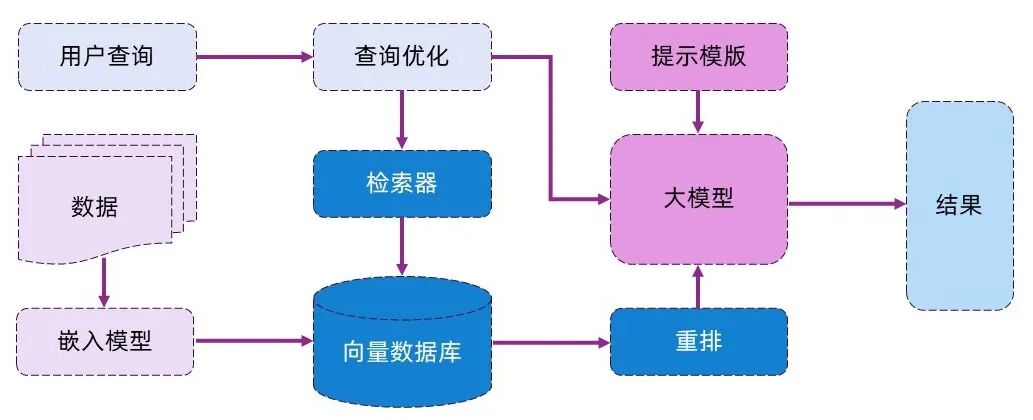
结合上图,我们拆解下RAG的完整工作流程:
- 用户输入查询需求(也就是我们常说的query);
- 系统先对query进行简单优化(比如修正表述、补充关键信息),让查询更精准;
- 优化后的query会发送到检索器(Retriever),由检索器从提前准备好的数据库中,筛选出和query相关的所有数据;
- 检索到的相关信息、优化后的query,再加上提前设定好的提示模版,一起组装成大模型能识别的“上下文(Context)”;
- 最后,大模型根据这份完整的上下文,生成最终的回复。
embedding
embedding 向量化,在大模型中,我们一个词表达意思可能会有区别,比如苹果既可以代表水果,也可以代表手机,所以某个词是什么意思取决于这个词所在的语境是什么。
我们怎么知道词与词之间有没有关联呢?我们可以将词转化成一连串的浮点型数字,去计算词与词之间的距离。
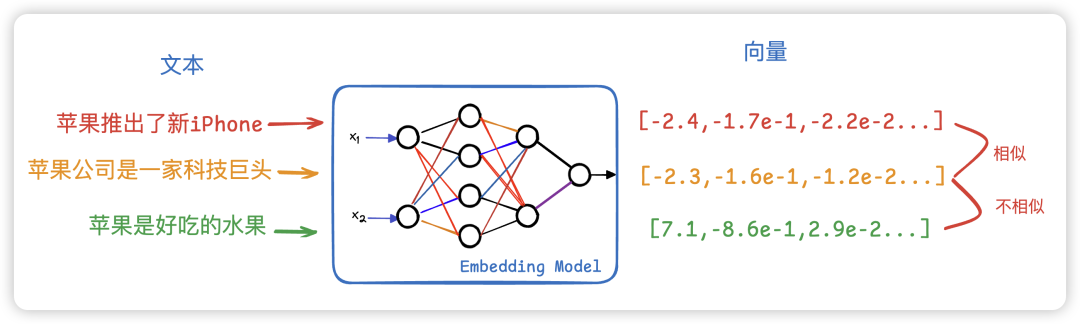
举个例子:
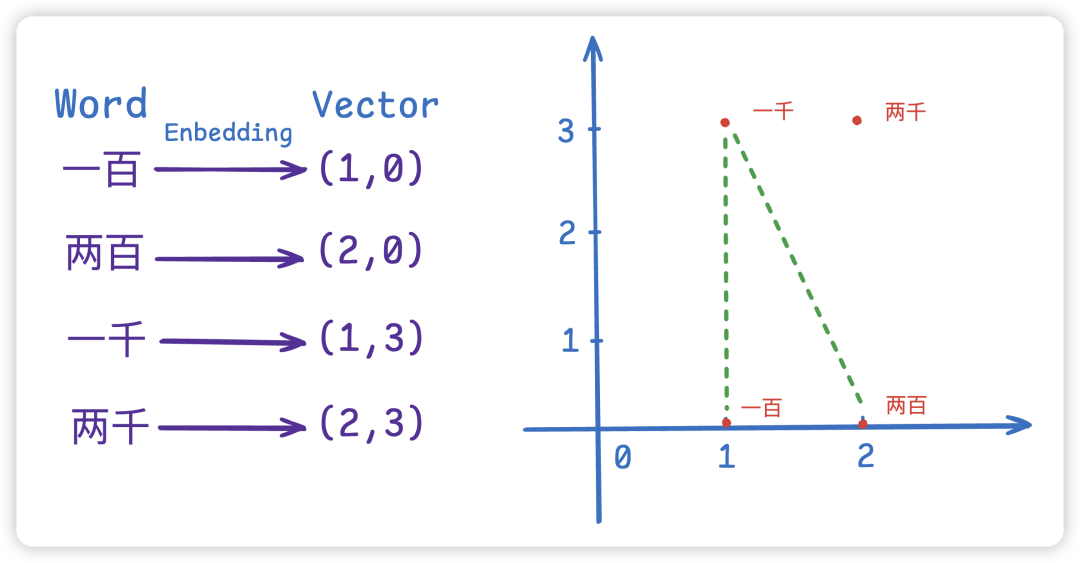
我们可以看到单词向量化后就变成了浮点型,在坐标轴上画上这些坐标我们可以很直观的看到:一百和两百的距离近,而一百离一千远,所以一百相比于一千,更接近两百这个语意。
LangChain
LangChain 是一个快速实现 agent 的开发框架,提供了标准接口,用于将不同的LLM连接在一起,以及与其他工具和数据源的集成。
vLLM
vLLM 是虚拟大语言模型的简称,由 vLLM 社区维护的一个开源项目。是一种专门为大语言模型设计的高效推理引擎和框架。为了让大语言模型(LLM)更高效地大规模执行计算,通过更好地利用 GPU 内存 来加快生成式 AI 应用的输出速度。 最主要是两个模块:KV Cache和连续批处理。
KV Cache:
这里的 K 和 V 是由每个 token 的向量化后通过线性变换得到的两类向量,用来做注意力计算。 KV Cache 把这些历史 K/V 保存下来,后续步不用重复计算。但 KV Cache 随上下文长度、层数、头数、维度线性增长,也变成推理中的最大显存开销之一。
vLLM 的做法:
- 分块:用 PagedAttention 将每条序列的 KV Cache 切分为固定大小的 块(block) ,并用页表式映射管理它们,像操作系统的虚拟内存一样灵活调度。这样避免了按序列分配一大块连续内存导致的碎片化和 OOM,同时支持动态并发与复用。
- 复用与共享:在多分支(如 beam search)和重复前缀场景下,可复用相同前缀产生的 KV 块,极大减少预填充(prefill)时间。
连续批处理:
- 不是攒满一批再跑,而是在每个解码步骤(按 token 迭代)都把活跃请求组装成一个批,序列长度不同也能高效合批,GPU 基本满负载运转。减少 短任务被长任务阻塞 的头阻塞,提高并发与公平性;
- 基于PagedAttention 的块式内存 + 步进级调度器,无需等待整批结束即可把新的请求插入下一步的批次。
Ollama
Ollama 是一个强大的运行框架,旨在使运行LLM尽可能简单。Ollama 简化了在本地机器或服务器上下载、运行和管理大型语言模型的整个过程。
vLLM与Ollama对比
vLLM 和 Ollama 都是在大语言模型推理与服务领域较为知名的工具,但它们在多个方面存在差异:
1、定位与目标用户
vLLM
定位:是专注于高性能大语言模型推理和服务的库,主要目标是通过优化算法和并行计算技术,提高推理速度和吞吐量。
目标用户:更倾向于有一定技术实力的开发者和数据科学家,他们希望在自己的项目中集成大语言模型,并对模型的推理性能有较高要求,比如开发大规模在线语言服务、进行模型评估和研究等。
Ollama
定位:是一个可以在本地运行大语言模型的工具,提供简单易用的方式来运行和管理各种语言模型,强调便捷性和低门槛。
目标用户:面向更广泛的用户群体,包括普通开发者、业务人员甚至非技术人员。这些用户可能更关注如何快速将大语言模型应用到实际场景中,而不太在意底层的技术细节。
2、功能特性
推理性能优化
vLLM:采用 PagedAttention 算法,能有效减少内存碎片,提高内存利用率,同时支持模型并行和流水并行技术,可充分利用多个 GPU 的计算资源,在处理大规模并发请求时具有显著的性能优势,能实现高吞吐量和低延迟的推理。
Ollama:也注重推理性能,但在优化方式上相对更侧重于通用性和易用性,通过优化模型加载和推理流程来提高速度,不过在大规模并行计算和极致性能优化方面可能不如 vLLM。
模型支持范围
vLLM:支持多种常见的大语言模型架构,如 LLaMA、Falcon、GPT - NeoX 等,对 Hugging Face Transformers 库有较好的兼容性,方便开发者使用不同的预训练模型。
Ollama:提供了丰富的模型选择,涵盖了多种流行的开源大语言模型,用户可以方便地下载和切换不同的模型,并且对模型的管理和使用较为简单直观。
API 与易用性
vLLM:提供简洁的 Python API,对于熟悉 Python 编程和深度学习框架的开发者来说比较容易上手,但需要一定的编程基础和对模型推理的理解。
Ollama:不仅提供了 RESTful API,方便开发者进行集成,还具有命令行界面和简单的配置文件,即使没有编程经验的用户也能快速启动和使用模型,其可视化界面和应用模板进一步降低了使用门槛。
3、应用场景
vLLM
适合构建大规模的在线语言模型服务,如智能客服系统、聊天机器人平台等,需要处理大量并发请求的场景。
在模型评估和研究阶段,能够快速对不同的大语言模型进行推理和测试,帮助研究人员节省时间和计算资源。
Ollama
适用于快速将大语言模型应用落地的场景,如企业内部的智能问答系统、简单的文本生成工具等,业务人员可以根据需求快速创建和调整应用。
对于本地开发和测试环境,Ollama 可以方便地在本地运行模型,进行快速验证和调试,无需依赖云端服务。
4、总结
如果生产环境,高并发、高流量,推荐使用vLLM并且搭配GPU使用。 如果流量较低,并且资源有限,只能使用CPU进行推理,使用门槛低,可以推荐使用Ollama.
Ollama可以快速进行搭建一个样例出来,提供给非技术人员,例如公司领导、运营或者产品人员进行演示,降低搭建成本。
vLLM的入门门槛相对较高,需要具备相关的运维知识,否则光装个驱动、编译环境啥的都让人望而却步了。遇到的问题比较多。
Token
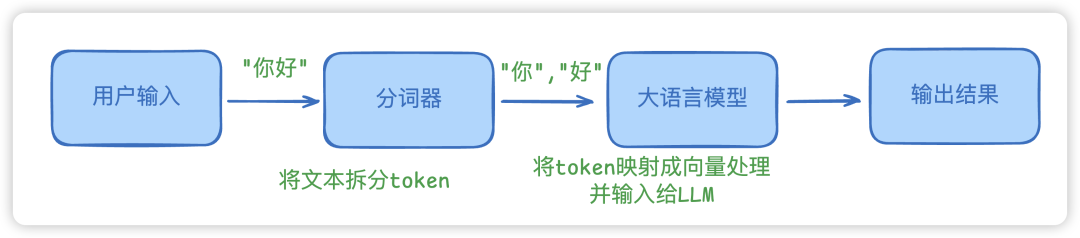
Token 是大模型各种算法的基本输入单元,可以认为是一个单词或者一个短语。一般来说:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
数据蒸馏
Data Distillation 数据蒸馏,利用一个高性能的大模型生成精简但有价值的数据,使得一个小模型可以从中学习并逼近大模型的效果。
Skill
New API
New API - AI 基座 https://docs.newapi.pro/zh

 鲁ICP备19063141号
鲁ICP备19063141号
 鲁公网安备 37010302000824号
鲁公网安备 37010302000824号